It’s kind of ridiculous that in 2023 I can’t put two user profiles in a brand new iPad so that my wife and I can share it without being all up in one another’s grills.

A wet and cool spring means that there is still some snow on the peaks, but summer is now coming in hot, so it won’t last much longer.
I’ve decided to experiment with two new tools for a little while: Aboard for bookmarking and filing interesting things (and I’m always interested in things that Paul Ford gets excited about); and Omnivore as a new read-later platform. Something about a new clean slate in each of those categories is really appealing, so I’ll see how it goes.
Vacation days are great! Today I improved RideShare, my Shiny app that makes shareable ride cards from my Peloton workouts. I had to update to accommodate the new images that the API sends, and I added a clickable history to build cards for any recent ride. I don’t like the styling of these new images quite as much – they’re not as powerful-looking cycling-specific images as the old feed provided – but I’m still really pleased with what I can build with it!
Python + R in Quarto
I’ve been using Quarto for just about everything I can for the past year, advocating for it enthusiastically with anybody who will listen, but today was the first time I started experimenting with combining python and R in a single Quarto document.
Look, I’m somewhat on record as not liking jupyter notebooks. I don’t like how the file format requires an interpreter, which I feel hurts readability and portability. So I’m predisposed to really like something that reduces that friction, and, wow — python in Quarto hits it.
And passing data, interactively, between R and python kernels within a single interface of a Quarto document? That’s mind blown meme territory right there. It might motivate me to learn more python in an environment I like to work, and should also be a great gateway to go the other way: The python to R pipeline! I’m envisioning some learning and tutorial work that takes advantage of both approaches, just deeply excited about what it opens up for doing data work and data people.
See more: Nicola Rennie’s post is a great overview, and I also learned from Danielle Navarro’s writeup of using reticulate.

Diablo IV on the Steam Deck is a great time.
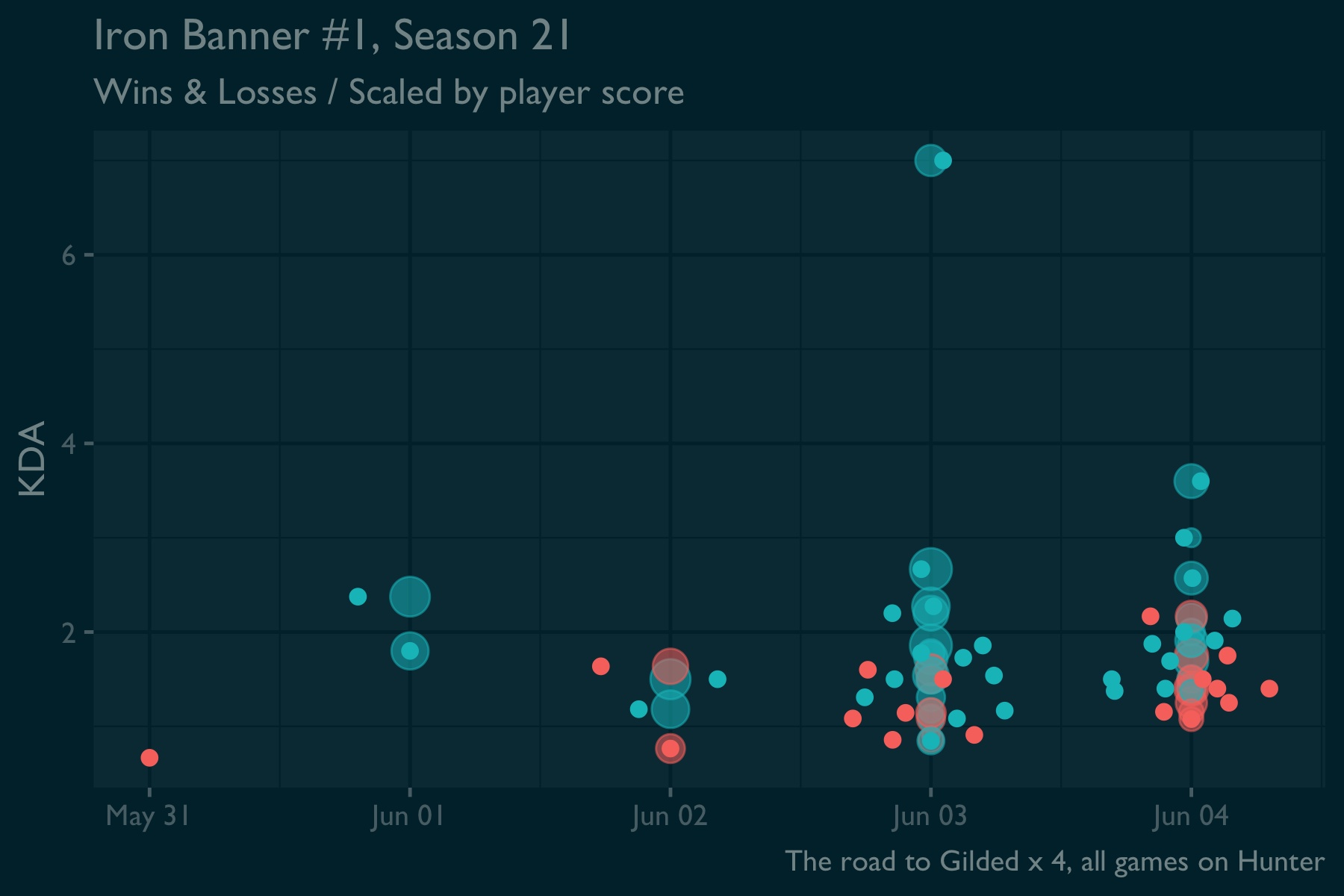
Destiny 2 talk: I had a good time in Iron Banner games this weekend. Most of my matches were fun. I didn’t have any long losing streaks like last season, and really liked the build I settled on. Maybe next time I’ll play my other characters, but it’s all for fun now that I completed the gilded title one more time!


