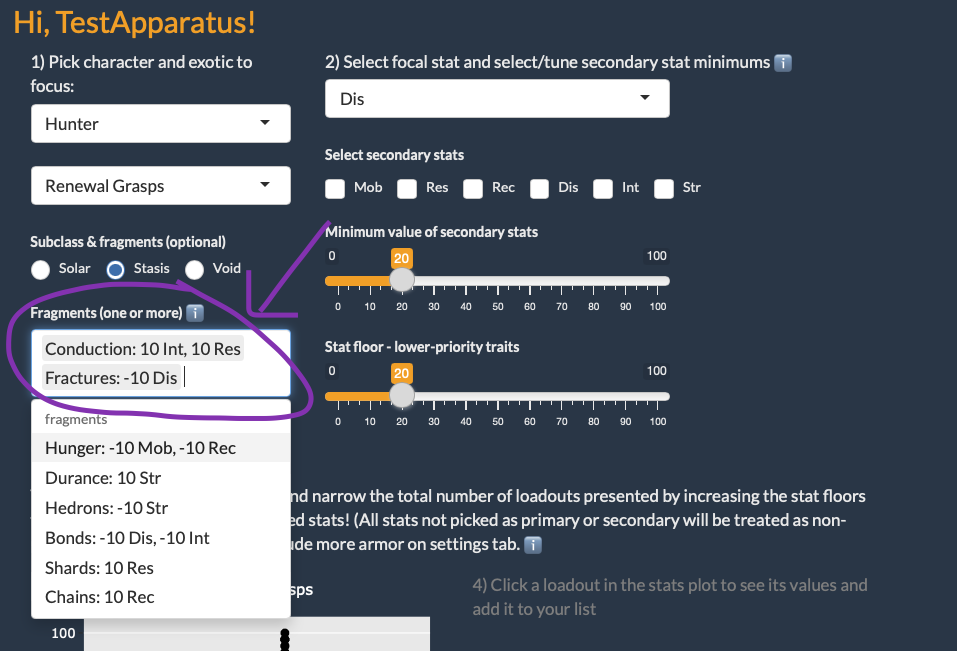
I finished a big update to Armorer this week, to enable inclusion of subclass fragments in stat calculations. I learned a ton with this release and laid good groundwork for additional mod management. I’m pretty pleased!
Super-pleased to see that a couple of small Shiny app improvements I made this weekend correctly picked up on some source data changes today and automatically handled them. Pretty cool!
🎮 I got to spend a few hours this weekend laying siege to the new dungeon that was released in Destiny 2 on Friday. Today, my team and I finished it! It’s the first time I’ve been able to play new, hard content at release and without any prior knowledge of it – and to actually complete it! I’m really happy that I got to do it, and I really enjoyed the time with my team to figure it all out together and successfully make our way through it.
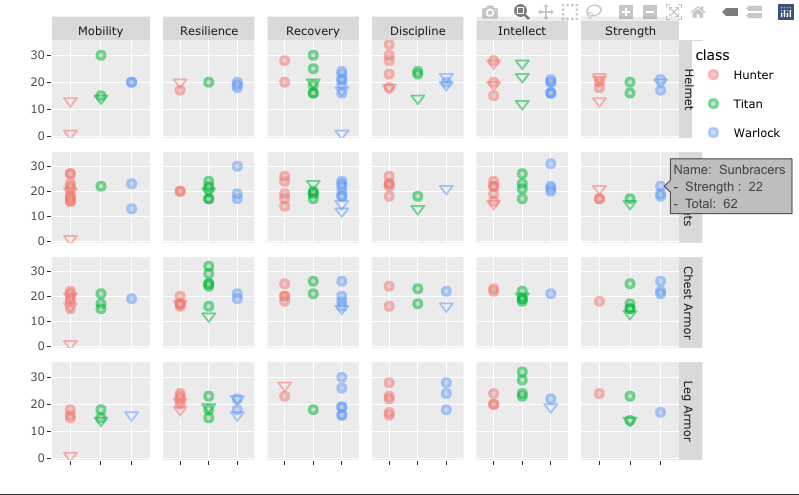
I had a good time this weekend coming up with a new way to visualize armor stat distribution in my Destiny 2 profiler tool. 🎮
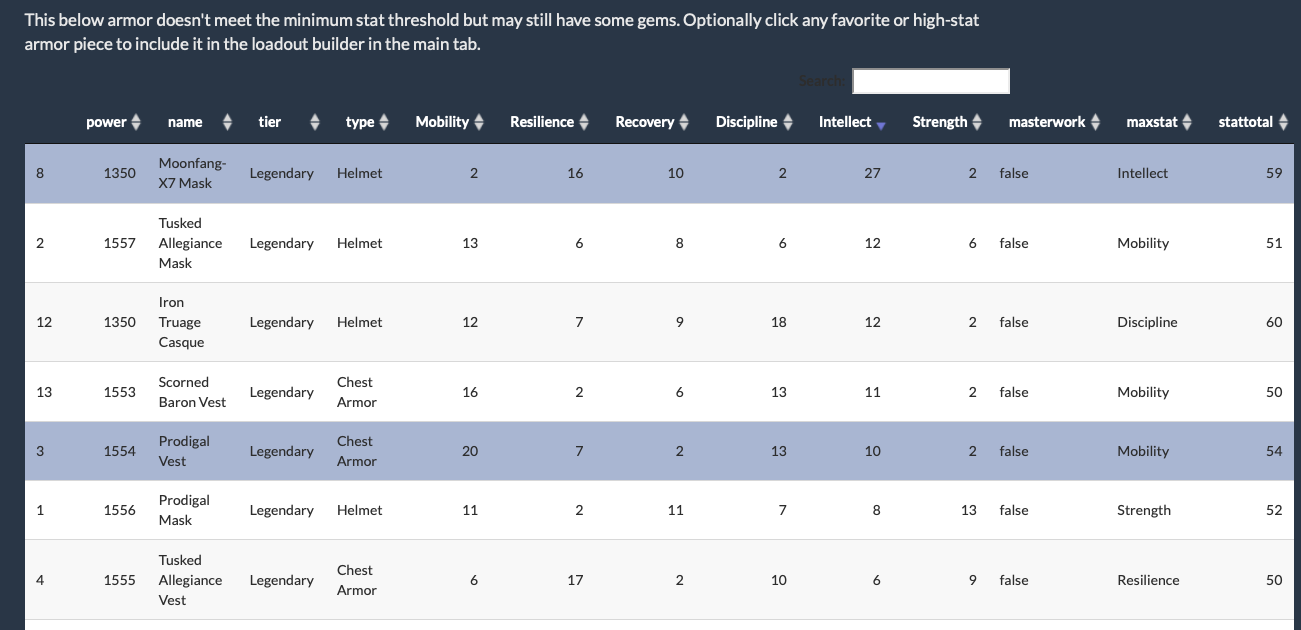
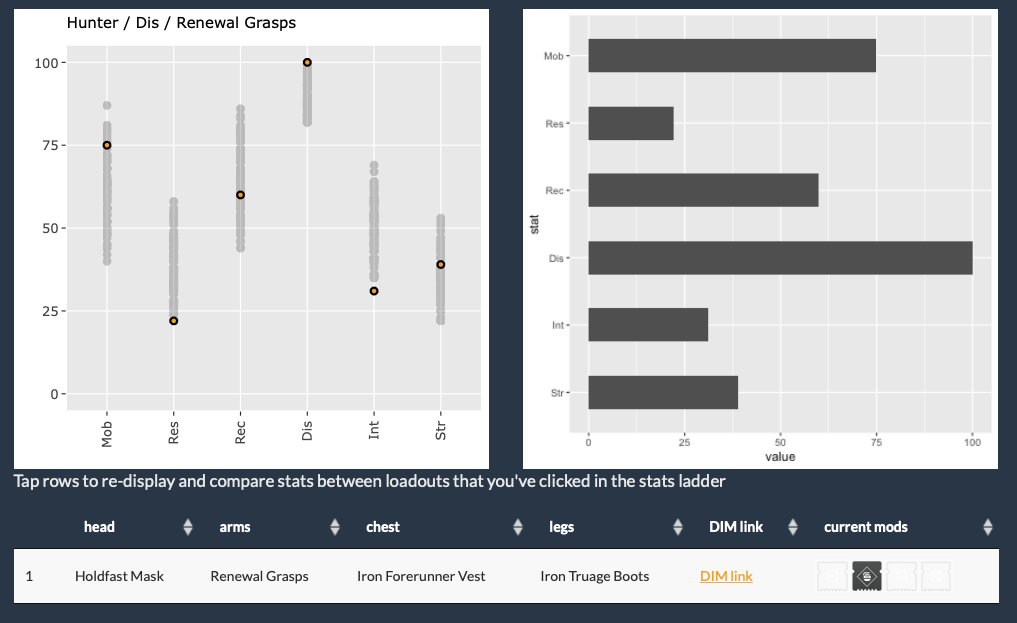
I’ve had a nice afternoon working on my hobby R/Shiny project, a loadout finder for the game Destiny 2. These improvements make it a lot more flexible and informative: It can now optionally include armor that would otherwise be filtered out of configurations by the minimum stat threshold, and it will show current mods used in displayed loadouts.
Since I’m talking Destiny projects lately, here’s a another open invite to Destiny-curious micro.friends who may want to try it out! The new expansion is very good and it’s a great time to jump in. Happy to be a space magic shooty guide to anybody who needs a friendly way into the game!
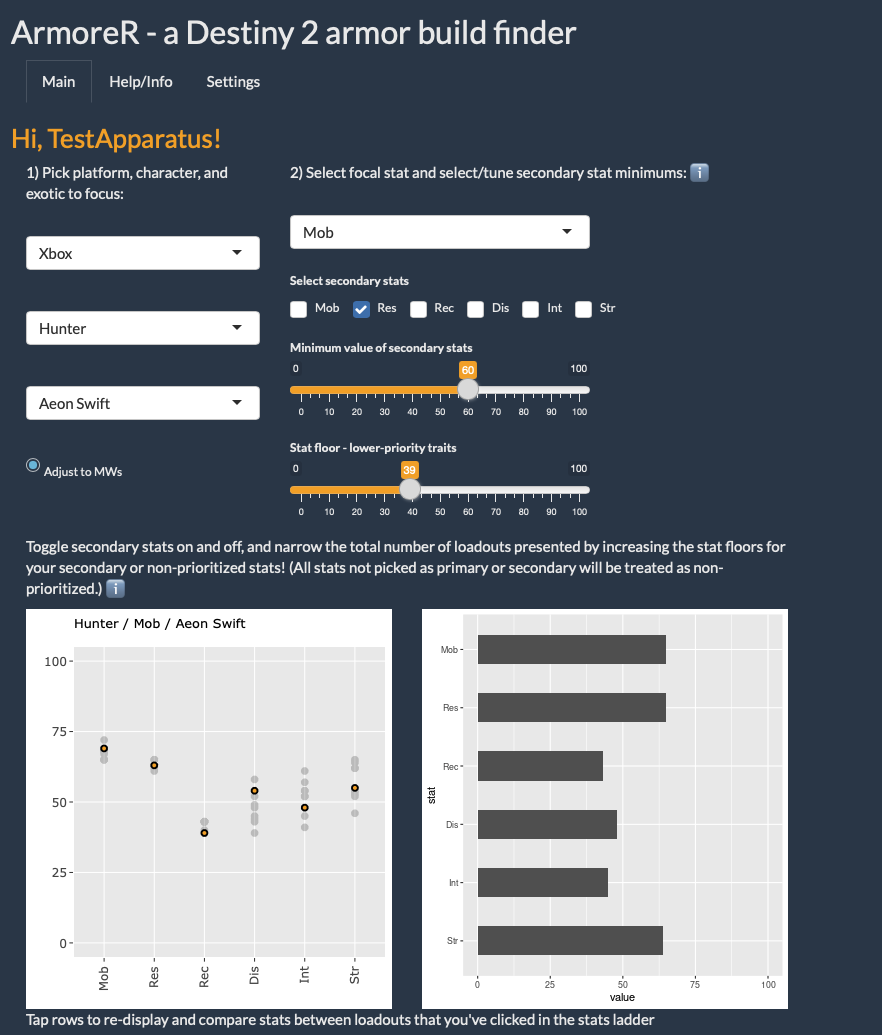
This revision of ArmoreR is really turning into something I’m happy with and proud of. I’ve learned so much since the very first iteration of this about a year ago. It’s really fun and rewarding to come back to it with a bunch of new expertise and make it much better in all ways, including a new approach to dealing with such a large amount of information.
(best Letterkenny voice)
Sundays are for fixin’ Shiny!
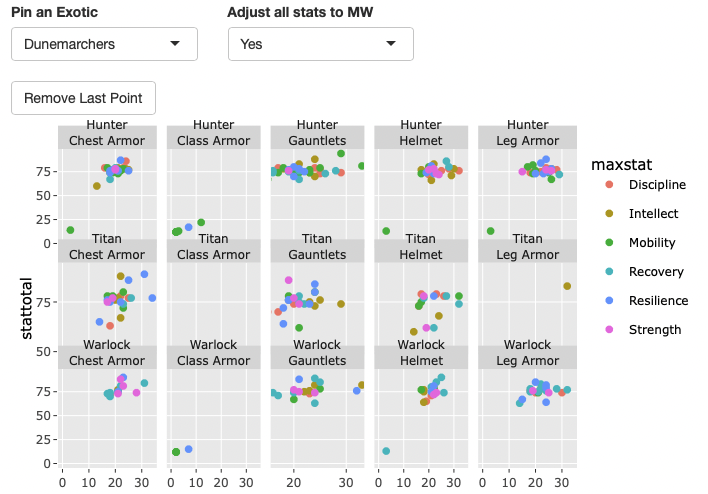
I spent a bunch of the weekend beginning a redesign of my ArmoreR project, which aims to be a Destiny 2 armor stats profiler built in R and Shiny. A year on from when I began it, I have a much better understanding of how a Shiny app works, and have also incorporated a proper, working oauth2 workflow into this revision (incorporating the things I figured out for my power level tracker). It’s really, really satisfying to be rebuilding it with all the things I’ve learned. I think the application is going to be so much better and less complicated than the first iteration. I still have a ways to go, and am happy with just how much I have transformed it with a year of learning and practice on other things.
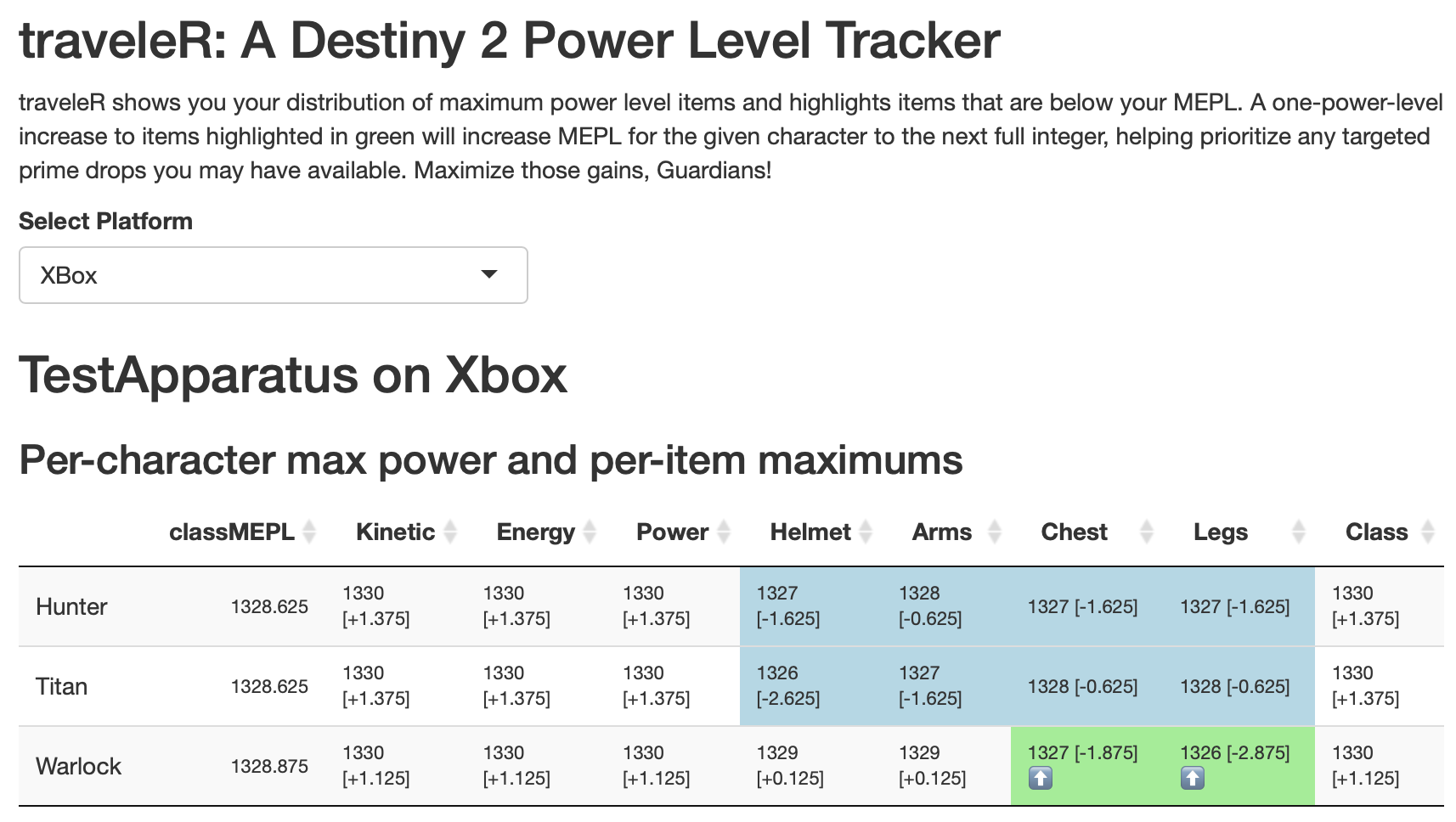
Last fall I wrote a bit about a Destiny 2 power level tracking tool I built using R. I’ve now converted it to a full-on Shiny app and solved some issues with the oauth2 flow that stumped me in my intermittent tinkering with it. I’m super satisfied to have been able to get this to work! Now that I have the authentication process figured out, I’m eager to also convert my armor profiling tool to use it. Look out!
You can check it out here: traveleR