My little Shiny app to visualize my last.fm data continues to tick along. This graphic shows the top artists of my year not in my top all-time played list. My favorite new album of 2024 is at the top of this list: Nick Cave’s WILD GOD is a tremendous, moving record.
If you’re still scrobbling, you can see your own data at deardestiny.shinyapps.io/tuner.

I’m starting on some of my end of year data projects. First up, a bit of output from the summary visuals I’m building of my workout data! I know, I know, polar plots are bad data representations, but I really like the clock-like image for this depiction of workout times.

I hit this Turkey Burn ride pretty hard this morning and am resting deep in post-ride endorphins, now. Time to sip on my coffee and think on some thanks. I’m glad I get to do this.

Matt Dray has found that Shiny apps can run at itch.io! This is very cool. It would be really fun to have a kind of Shiny game jam.
Got in a solid ride first thing this morning, plus some cool-down time and stretches. I’m sitting now with the endorphins and calm that come in after a hard workout, appreciating the quiet and still after furiously working in my body.


Got on the bike for impromptu ride #200 this morning! This was my first live ride in quite a while, and was a lot of fun – and a good amount of work, too.
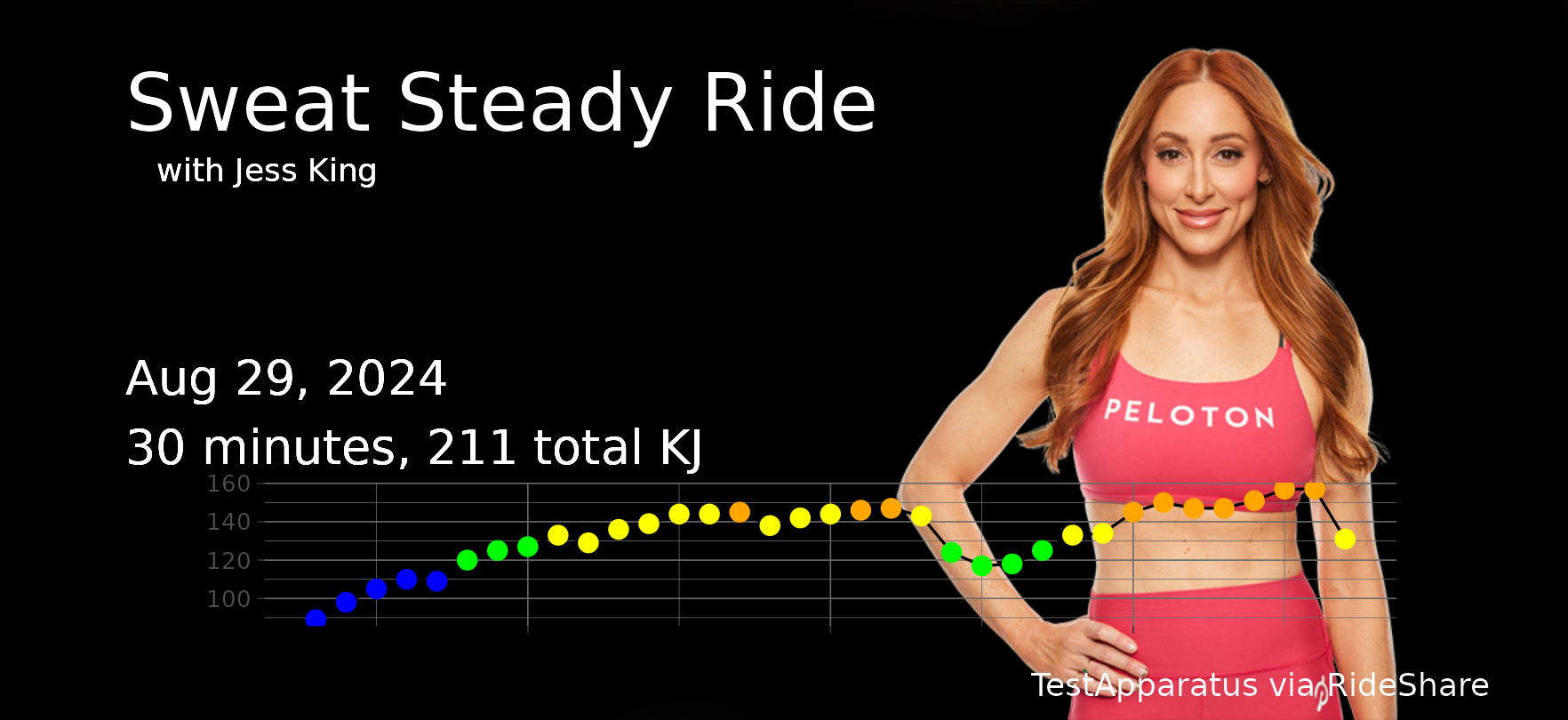
I’ve been making some small visualization and operation improvements to RideShare, my little Shiny app for making shareable cards from my Peloton rides. I discovered the API for more detailed heart rate data and incorporated that into the display, and made a couple of changes to speed up the history display. These were fun small updates to work on!
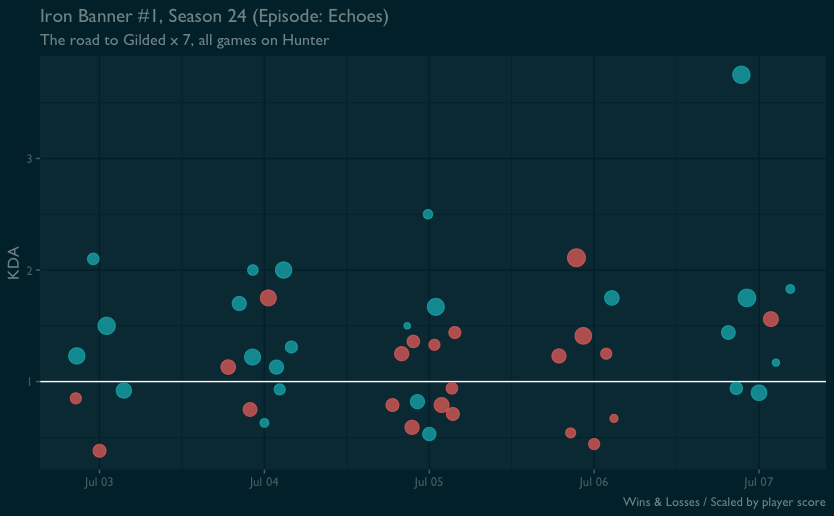
I had a pretty good time getting to the gilded title again in this week’s Iron Banner, the first of this newest The Final Shape expansion.
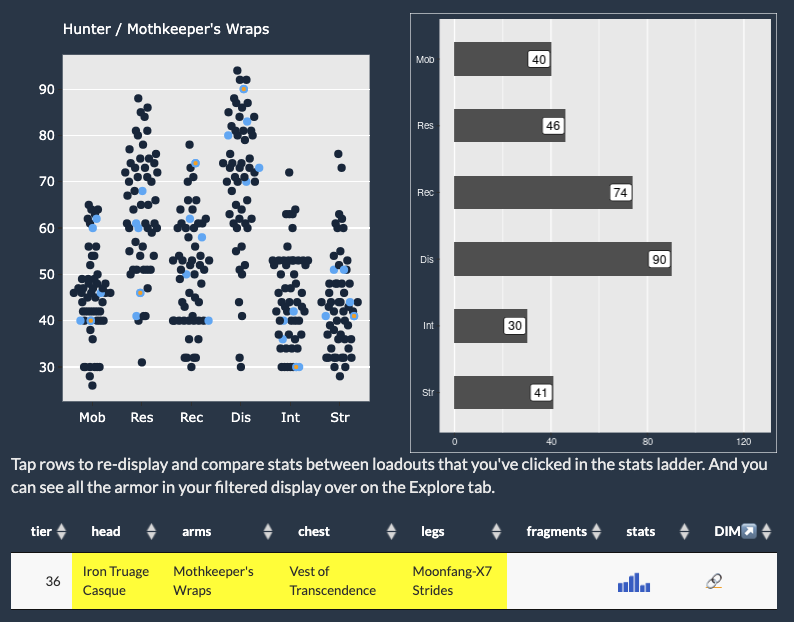
With the release of the tremendously good The Final Shape expansion, I’m in the mood to make some updates to my Destiny 2 tools. First up is Armorer, with a re-work of some filtering options to limit possible loadouts by tier, which seems to get right to an effective loadout more quickly than my prior approach. It’s a little limited, but I really like the direction this allows me to go. And it’s fun to work on again!