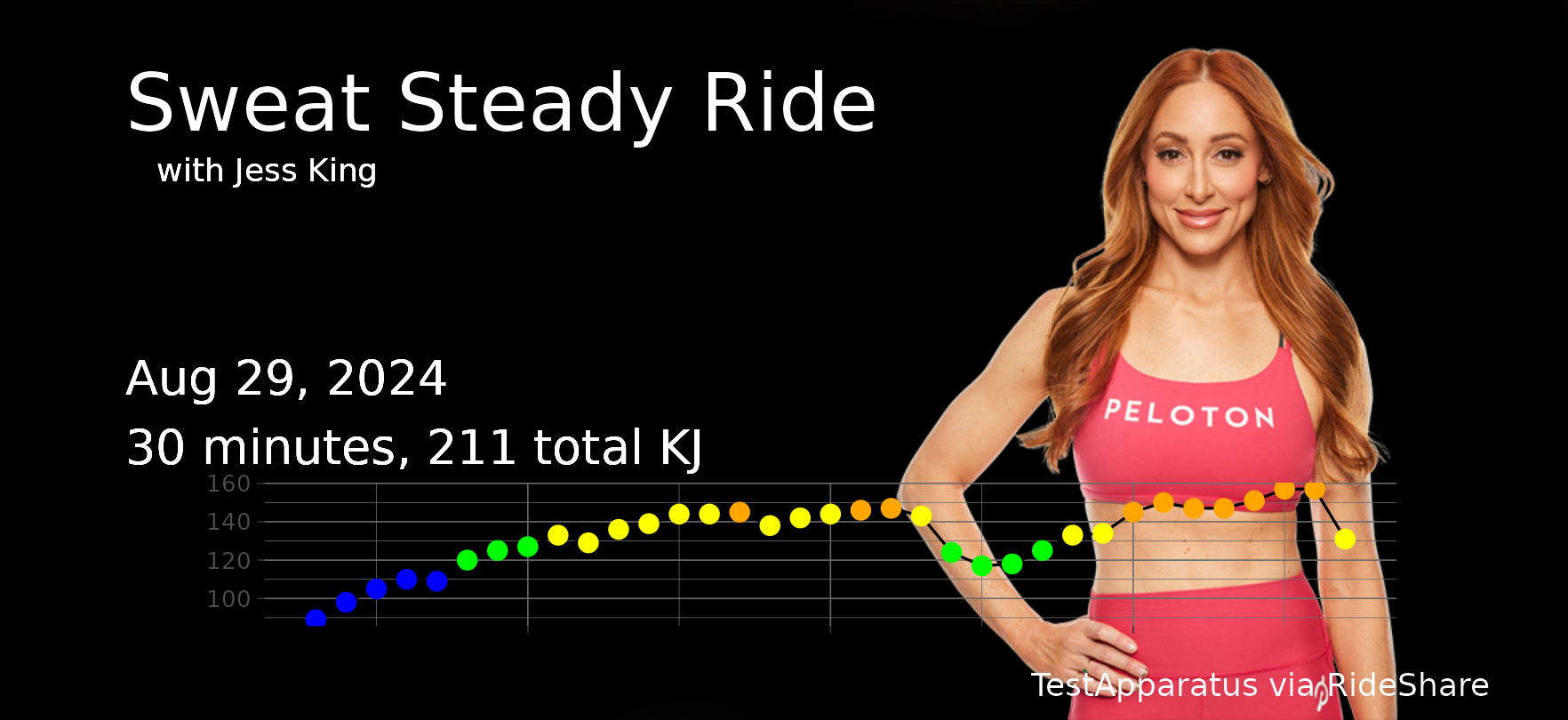
I’ve been making some small visualization and operation improvements to RideShare, my little Shiny app for making shareable cards from my Peloton rides. I discovered the API for more detailed heart rate data and incorporated that into the display, and made a couple of changes to speed up the history display. These were fun small updates to work on!
- Huge revision of the backend method for stat calculation, making it more flexible and accurate
- Highlighting of masterwork items in display
- Proper forwarding of selected ability fragments to DIM for loadout building (this was harder than I thought it would be)
I’m quite interested in Positron, the new data science-focused IDE from Posit, built on the open source VS Code foundation. It’s certainly a pitch to get more Python/VS Code-focused developers into the Posit ecosystem, though I also wonder if those users’ preferences aren’t basically already baked; Positron is going to have to be clearly differentiated for Python/VS Code developers to care, and that will be an interesting path to see take shape. To be clear, I hope it does! For my own uses, I’m eager to see Positron fully support working with R (my own experimentation: ongoing!) and bring more ready-to-use affordances and updated UI to the R experience.
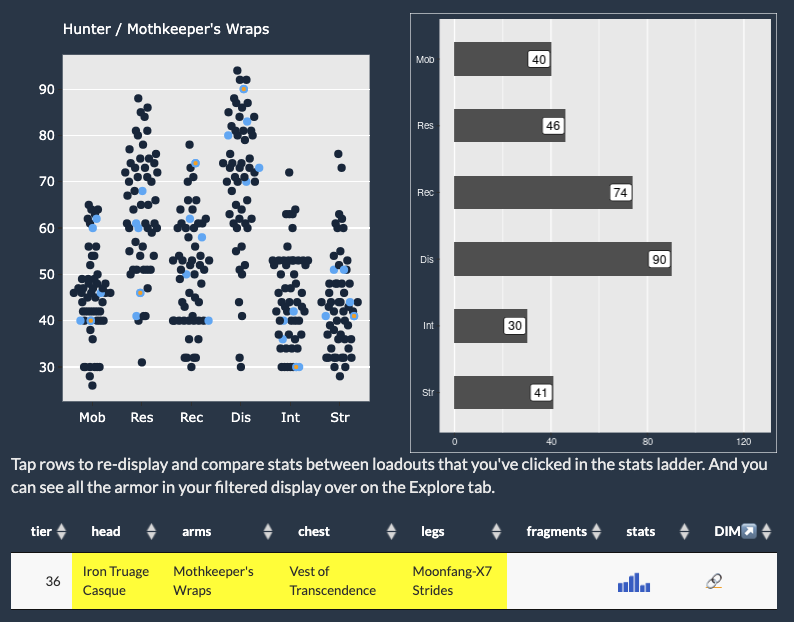
With the release of the tremendously good The Final Shape expansion, I’m in the mood to make some updates to my Destiny 2 tools. First up is Armorer, with a re-work of some filtering options to limit possible loadouts by tier, which seems to get right to an effective loadout more quickly than my prior approach. It’s a little limited, but I really like the direction this allows me to go. And it’s fun to work on again!
I’ve been thinking some about “expressive” work with code and why I think it’s useful and important, and I wrote up a little blog post about it, over at my Datablog: What do we mean when we say ‘code is expressive,’ anyway?.
I wanted to make a QR code to go along with a gift card I’m giving to someone. The search space for how to do that is a wasteland of SEO and sketchy generators, but – turns out – there’s a MacOS/iOS shortcut already available in the Shortcuts gallery. HOWEVER: Searching for just “QR” doesn’t find it; search for “QR code” instead, and you’re good to go.
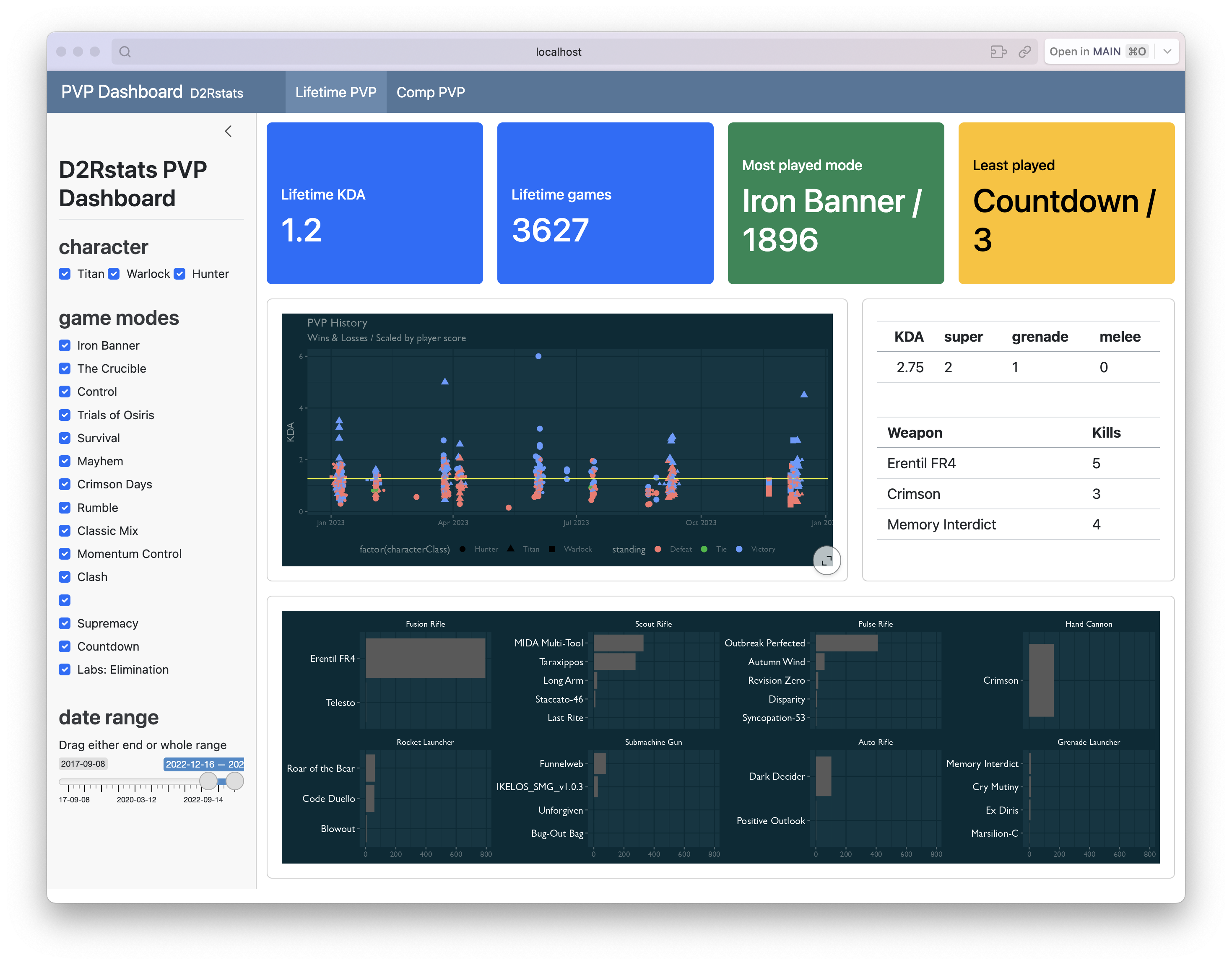
This PVP dashboard isn’t quite yet committed to my D2Rstats project, but it’s close to being ‘ready enough’! As usual, I’m impressed and excited at what Quarto can do. It’s really fun to develop this way.
The last couple of weekends I’ve been slowly working on some improvements to Armorer, my Destiny 2 loadout finder build in Shiny.

Notable enhancements for this release include:
There are some bugs to address and optimization to perform, of course. But, with these improvements, the tool is finally just about as functional as I have long wanted it to be! I think it’s really pretty good, and I’m pleased and proud to have made something sophisticated and useful. I hope some more Destiny 2 players will try it out and let me know how it works for you.
I had some really nice hours this weekend working on my Destiny 2 loadout finder project, Armorer. All my current work is on the backend, and will result eventually in a lot more flexibility in armor piece stat calculation, and – I hope – faster performance. This big Shiny application is complex enough that I can see the rest of the work to do right in front of me, and I know that completing all the revisions is still a pretty substantial piece of work!
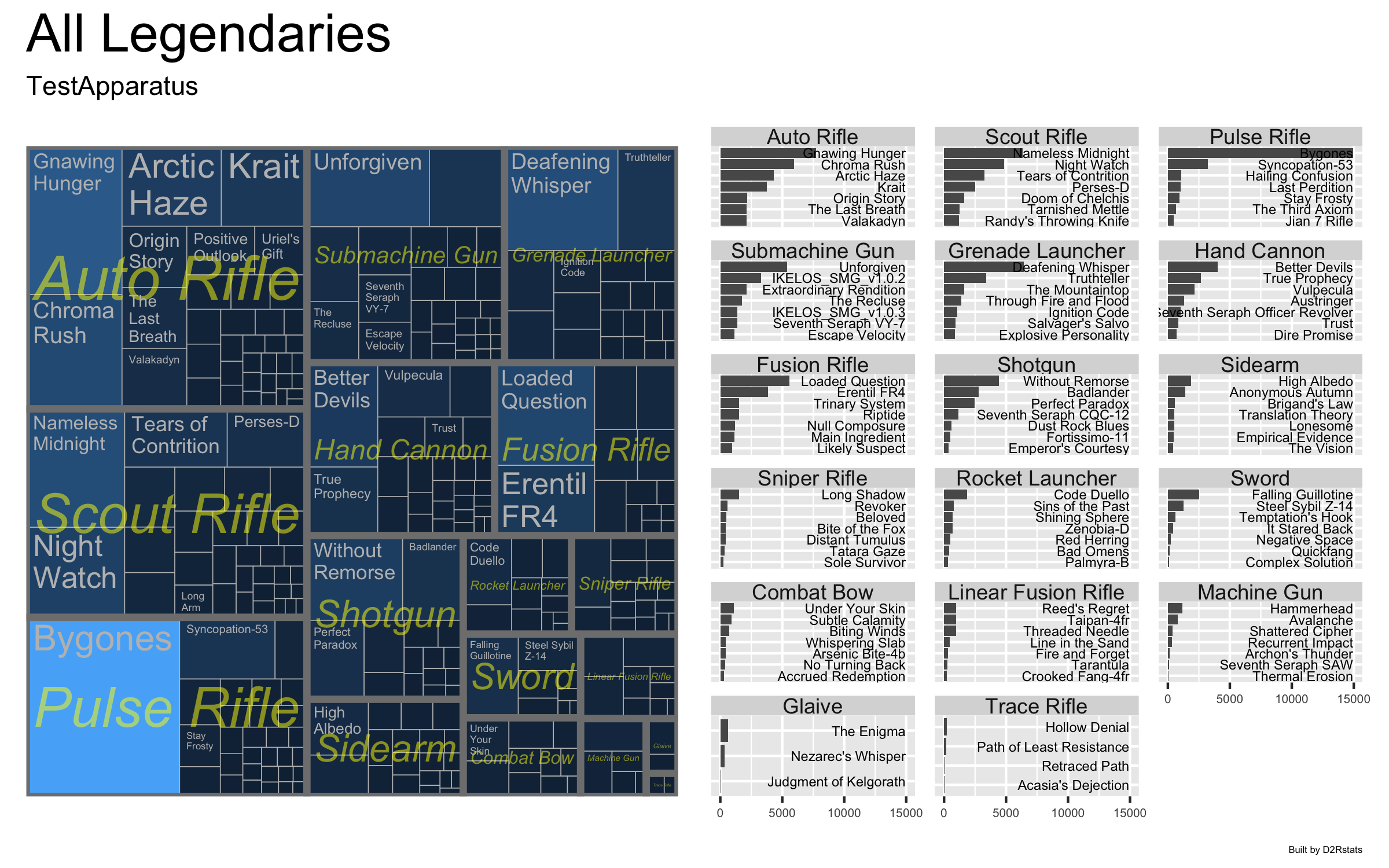
I’m publishing a project I’ve been tinkering with for a while and finally decided to make “good enough” to share! D2Rstats is a set of Quarto notebooks that fetch, store and make fun and useful data out of your Destiny 2 postgame carnage reports, such as this all-time weapon treetop. If you’re comfortable enough with R, it can be a jumping off point to exploring your own game data further. It’s been a lot of fun to refine this, and I’ve learned a ton along the way.
You can find all my Destiny 2 related projects over at deardestiny.blog.